
Kode Chemoinformatics, business unit della pisana Kode, dedicata ai progetti di chemioinformatica e intelligenza artificiale in ambito chimico, farmacologico, alimentare e biotecnologico, lancia Fast, un prodotto dedicato alla selezione dei descrittori molecolari rilevanti per la costruzione di modelli QSAR (Quantitative structure-activity relationship), un metodo rappresentativo assistito dalla bioinformatica nello screening tossicologico.
Il tema della feature selection, benché fondamentale nel definire le qualità del modello in un difficile equilibrio fra overfitting e underfitting, è tutt’oggi un problema aperto.
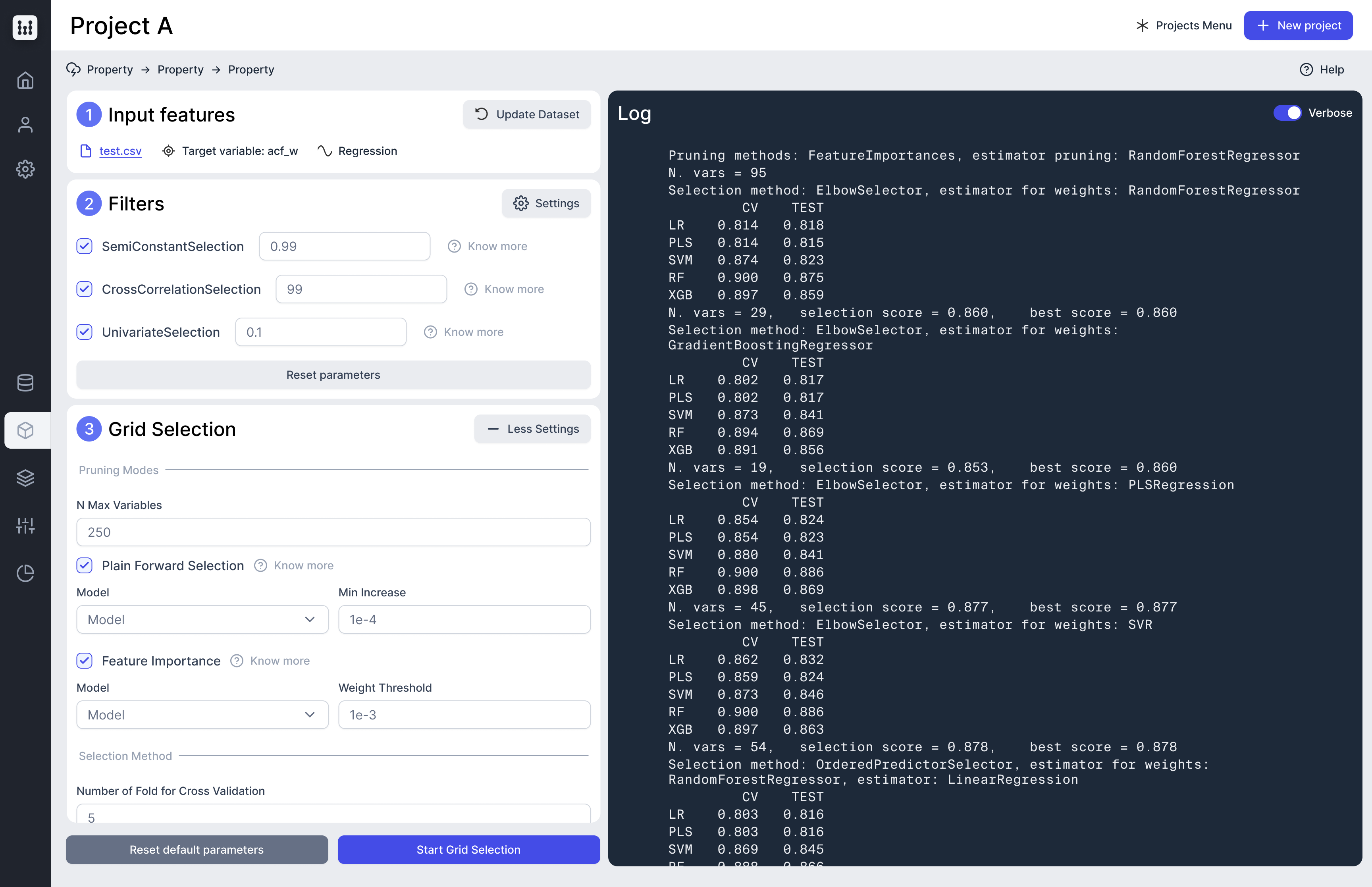
I problemi della modellazione QSAR
Fra le molte soluzioni proposte negli anni, non esistono condizioni che consentano di valutare a priori il miglior metodo di selezione per un dato problema. La selezione delle caratteristiche utili diventa quindi un passaggio centrale in un settore come la modellazione QSAR in cui il calcolo dei descrittori molecolari può generare migliaia di features, rendendo quindi il processo lungo e complesso.
La Business Unit di Kode Chemoinformatics ha risposto a questo problema con Fast, prodotto in grado di identificare con uno sforzo pressoché nullo da parte dell’operatore il miglior set di variabili per il proprio modello QSAR e di fornire soluzioni facilmente integrabili con qualunque flusso di lavoro. Utilizzando un approccio full-search, Fast scompone il problema della selezione delle features in tre passaggi sequenziali (filtering, pruning e selection) a precisione e costo computazionale via via crescente generando così un gran numero di set di variabili.
L’efficacia di queste soluzioni viene quindi calcolata in termini di proprietà predittive attraverso uno o più modelli machine learning al fine di identificare la soluzione migliore per il dataset in esame
“Fast è il primo di una serie di strumenti che stiamo sviluppando per semplificare la vita a chi lavora con dataset di grandi dimensioni con tantissime features nell’ambito della modellazione QSAR – afferma Alessio Sommovigo, responsabile della BU Kode Chemoinformatics. “Utilizzare un set di variabili non ottimale per il modello può impattare notevolmente sulla corretta modellazione”.